
Table of contents
1. Successfully recruiting quality test users
2. Experimenting with manual quality checks
2.1 Dealing with the limitations of manual checks
2.2 Ensuring more efficiency and effectiveness thanks to artificial intelligence
3. Reducing mismatching thanks to SmartInvite
4. Predicting reliability thanks to Honeybadger
4.1 Clustering data to predict quality
4.2 Finding the right factors which affect the test user quality
5. Taking artificial intelligence to the next level
5.1 Continuous learning with new data
5.2 Identifying further potential for artificial intelligence
6. Finding the right balance between human and machine
1. Successfully recruiting quality test users
Our test users are our core business and what differentiates us from other players in the market is the high quality of our pool of test users. And what does that mean? We ensure a representative and diverse pool of participants so that you get good insight for your user research. In other words, we provide you with test users that fit your required profile(s). And most importantly, we provide you with unbiased test users.
Moreover, moderators and observers of a test shouldn’t deal with no-shows, cancellations, and late test users. There will always be some situations in which the test user can’t attend the test but there are ways to reduce the risks of it to a minimum. To tackle this, we for example send our test users an email and SMS confirmation of their participation, as well as a reminder the day before. Among other things, this is one of the reasons why our no-show rate is below industry standards.
2. Experimenting with manual quality checks
In the past we have had many experiments with manual quality control checks to reduce misfits. For example, our customer success team has called every new test user assigned to a line up to onboard the user and explain the process of the test. This was very time-consuming and in the end had no effect on the quality of the test user. In another experiment we have asked test users to record a video of themselves, prior to the test. In this video they had to explain who they are and what their motivation is to participate. Unfortunately, this experiment even had a negative impact on the behaviour of test users. After the video experience, some of the users wanted to please the moderator of the test by telling them how good the product was, instead of being critical.
2.1 Dealing with the limitations of manual checks
With a pool of more than 985,000 people, it’s impossible to carry out manual checks of test users. When user researchers order test users with us, they want to talk to their users as soon as possible. For us, this means that we have to find out as quickly as possible which of our test users are suitable for the research. To ensure speed and quality as the pool size increases, automated processes are the only solution. For that reason, scalability and the access to thousands of datasets, pushed us to invest in data science in 2019. After seeing successful results in inference analysis we decided to do the leap and invest heavily in artificial intelligence in 2020.
2.2 Ensuring more efficiency and effectiveness thanks to artificial intelligence
To find out which of our test users are suitable and available for a test, we have to ask our test users questions. This process is called screening and consists of a collection of questions with built-in logic for sorting candidates in and out. Every recruitment of test users is combined with a screening, in which we check whether a test user meets the required profile by a customer or not. Our biggest challenge is to not spam all the 985,000+ test users with these screening questions. That’s why we use artificial intelligence to improve our service as a recruiter of test users and increase the experience of our test users with us. We specifically use two artificial intelligence mechanisms. One is for the profile prediction (SmartInvite) and the other is for the quality prediction (Honeybadger).
3. Reducing mismatching thanks to SmartInvite
Mismatching is a moment of frustration for test users. Especially because they take the time to answer the questions and hope for something in return. We do everything we can to reduce the amount of those moments of disappointment. This is where SmartInvite comes into place. With the help of SmartInvite we can predict if the fictive test user John Meyers actually owns a Tesla or not. John doesn’t even have to answer this question. You are now probably wondering how this works.
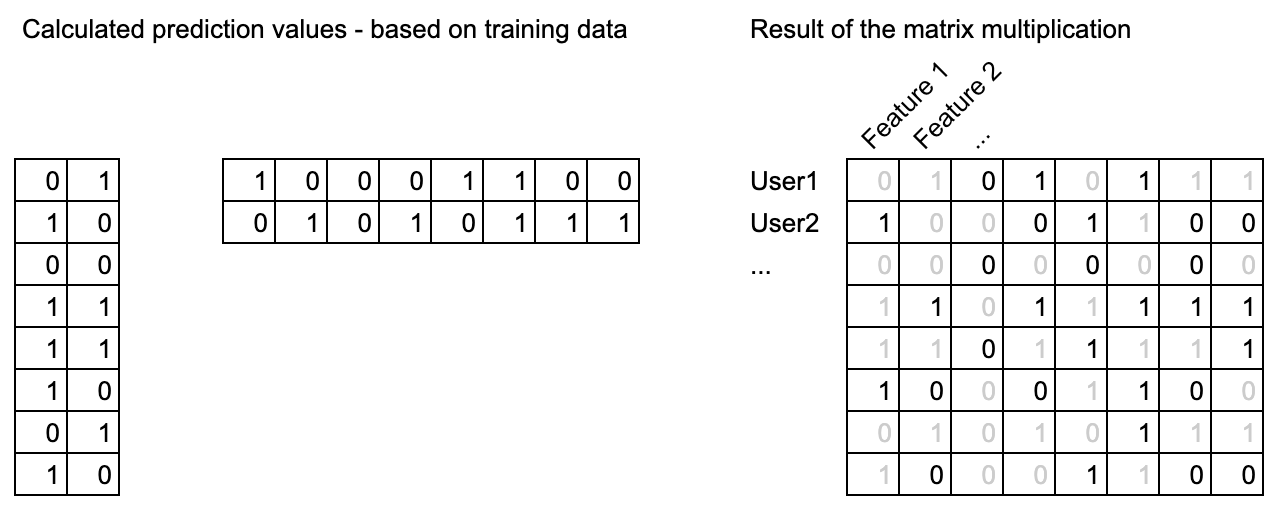
We base the profile prediction on all the data we have about the user and other users in our system. As of today, we have over 985,000+ test users and approximately 200 answers per test user. Our solution is a “matrix factorisation” to predict any possible answer, e.g. like owns a Tesla and owns a Mercedes but doesn’t own a Ferrari. It’s based on a crazy big data set of over 985,000+ users with 200 answers per test user which results in millions of particular answers (features) to predict.
This following matrix multiplication shows how it works. The grey numbers show things we don’t know 100%, but we can calculate with our prediction algorithm.
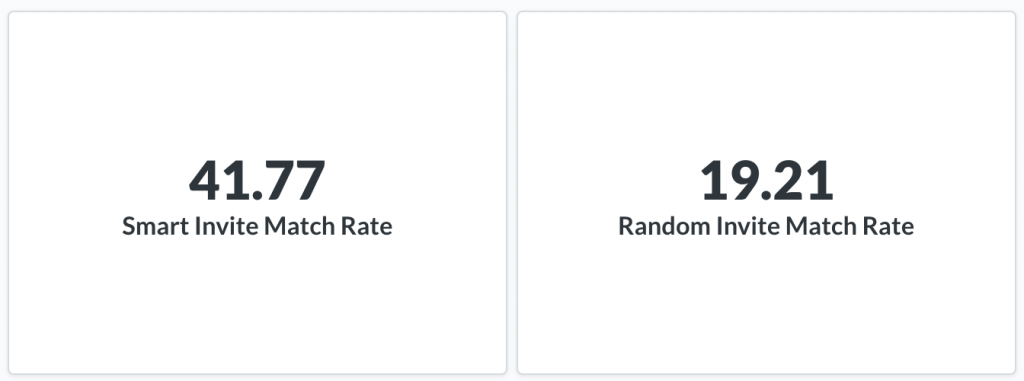
Thanks to this algorithm the probability of a test user matching a profile increased from 20% to 40%.
4. Predicting reliability thanks to Honeybadger
User research can be very frustrating, especially if one of these two things occurs:
- No-shows: test user doesn’t show up (too late, forgot, didn’t care, accident on the way, etc.).
- Misfit: test user didn’t fit the persona (misunderstanding, a lying test user, etc.).
The core of our service is quality. For us and our customers this means to deliver reliable and matching test users. We are fighting the above mentioned cases with many precaution mechanisms. One of them is powered by artificial intelligence too – we call it Honeybadger.
4.1 Clustering data to predict quality
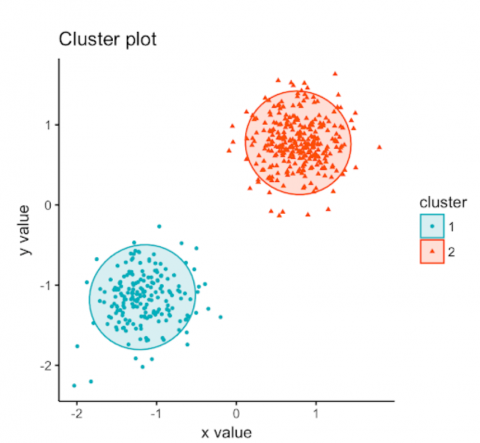
To find out who is qualified for the test, we classify the test users into two groups. We take all the data that we have about our test users and group them in two clusters. The reliable and the unreliable. And we only invite users from the reliable cluster. Just to be clear: depending on the study time, language, location a user can once be in the reliable or unreliable group. Here is a visual representation if there were only two dimensions.
4.2 Finding the right factors which affect the test user quality
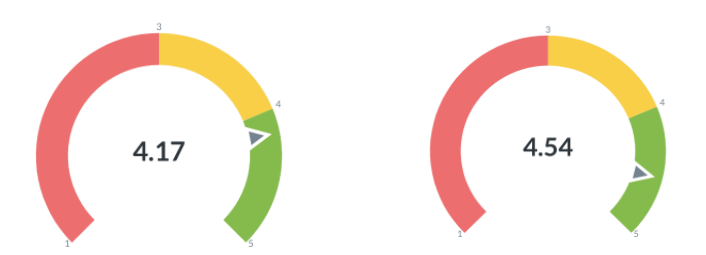
We have experimented with hundreds of influence factors on quality such as “distance to the next train station”, weather (do young people rather go to the lake on Wednesday afternoons if it’s sunny?), etc. After a while, we found seven that really give a good inference. Which ones stay our secret sauce. Users that were indicated as recommended get an average score of 4.54 out of 5, while the not-recommended users get an average rating of 4.17.
Just for the record: artificial intelligence is far away from always being perfect. It only gives indications and that’s how we have built our system. We don’t rely on the status quo and we constantly feed our system with learnings from errors.
5. Taking artificial intelligence to the next level
As already mentioned in this article, we continuously improve our test users quality and our service as test user recruiter. The following steps will show you how we ensure this.
5.1 Continuous learning with new data
We train our prediction algorithm every night with all the additional data that we learned within the day. So the longer we teach our algorithm and the more data we learn about our test users the more every test user and customer benefits from more precise invitations. This way we don’t bother them unless we need new information.
5.2 Identifying further potential for artificial intelligence
One thing is finding the right test users, the other thing is finding out when they’re available. Forecasting the availability of a test user could be improved with the help of artificial intelligence – as forecasting the match of a test user. With this service in place, we could help customers to find the time slots to run their user tests when their target group is mainly available (e.g. blue collars have usually strict schedules). Another potential artificial intelligence supported service would be to forecast the motivation and the thinking out loud capacity of test users. Last but not least, incentive suggestions could also be a game changer. Forecasting how much you should pay in incentives to your specific target group to attract the right test users could change the willingness to participate (e.g. surgeons and students don’t have the same hourly rate).
6. Finding the right balance between human and machine
The automation of customer support is great for improving efficiency. However, we believe that customers still want to be able to speak to a human if their queries cannot be solved completely online. The right experience at the right moment counts a lot. Therefore, we have an awesome team dedicated to our customer’s success only. Even though our processes are highly digitised and automated, our test users are still unique human beings. In case of any troubles, you can reach our customer success team who will handle the situation. In order to deliver the best possible customer experience, we want to invest further in our team. They can help you with the best profile mix, perfect screener questions, best study methodology to use, building your own pool of test users (Private Pool), and many more topics.
